Neural architectures¶
Note
TODO
… (todo)
Recurrent Neural Networks (RNN)
LSTM
GRU
GANs
Transformer (& attention)
VAE
… (todo)
Mixture Density Networks (MDN)¶
In the original paper by Christopher M. Bishop from 1994, Bishop defines Mixture Density Networks as a “class of network models obtained by combining a conventional neural network with a mixture density model. The complete system is called a Mixture Density Network, and can in principle represent arbitrary conditional probability distributions in the same way that a conventional neural network can represent arbitrary functions”.
Key idea
Instead of letting the network predict a single output value, the network is to predict an entire probability distribution over a range of outputs given the input.
Why is that useful? When auto-regressively generating handwriting, for example, we predict the next stroke based on the existing ones. Now, with MDNs, instead of sticking to one most likely prediction, the next stroke is drawn from a probability distribution of multiple possibilities.
Available resources at a glance
MDN concept¶
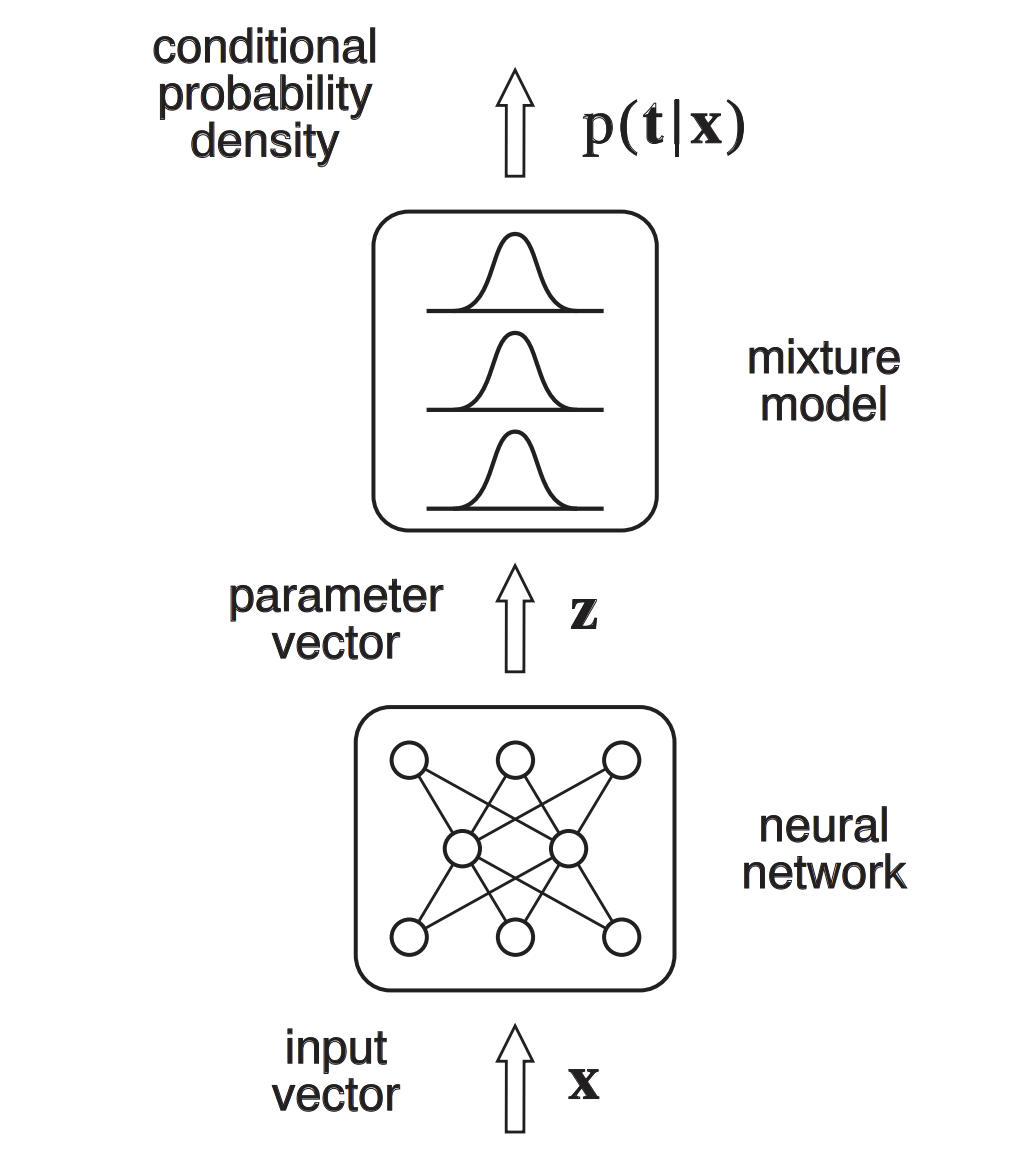
Fig. 4 “The Mixture Density Network consists of a feed-forward neural network whose outputs determine the parameters in a mixture density model. The mixture model then represents the conditional probability density function of the target variables, conditioned on the input vector to the neural network.” MDN figure and description taken from Bishop (1994).¶
MDN in PyTorch¶
Note
TODO
Combining MDNs with LSTMs¶
Note
TODO
TODO¶
Read these:
https://towardsdatascience.com/a-hitchhikers-guide-to-mixture-density-networks-76b435826cca
https://github.com/hardmaru/pytorch_notebooks/blob/master/mixture_density_networks.ipynb
https://blog.otoro.net/2015/11/24/mixture-density-networks-with-tensorflow/
https://blog.otoro.net/2015/12/12/handwriting-generation-demo-in-tensorflow/