Pascal Wichmann, PhD
Hi, I am Pascal.
I have always been interested in technology, business & entrepreneurship, and graphic design. These interdisciplinary interests are reflected in my research and professional career. And thus, I have become more of a Swiss Army Knife than a specialist.
I hold a German diploma in Business Engineering ("Diplom-Wirtschaftsingenieur"; academic degree equivalent to a combined Bachelor's and Master's degree) from Karlsruhe Institute of Technology (KIT), Germany. I also hold a PhD in Engineering from Cambridge University, UK where I was both a research assistant and PhD student at the Institute for Manufacturing (IfM) in the research group of DIAL. I am not a classical engineer though. My doctoral research was motivated by my research project for a large aerospace manufacturer. It aimed at extracting supply networks (who supplies whom) from natural language text, such as news articles, using deep learning. At the time, large language models (LLMs) did not exist or were just being experimented with, and so we had to collect and annotate text samples and train a classifier on that data.
My current research interests center on Machine Learning and AI and their applications in the creative domain. I am especially fascinated by generative models for vector graphics.
Professionally, I worked as a strategy consultant for OC&C Strategy Consultants and EY-Parthenon – most recently as part of the Advanced Analytics team. After leaving consulting to fully focus on AI again, I joined ARIC in Hamburg as AI Manager and later also Caps & Collars as Head of AI.
During my PhD, I co-founded a startup, called Versed AI which commercialized the core idea of my doctoral research. Due to my return to Germany after my academic leave of absence, I moved into a mentoring role. Versed AI got acquired by Exiger in July 2024. I used some of the proceeds for smaller investments in AI startups, such as Runware AI.
I am currently based in Hamburg, Germany .

Pascal and Loki, both with longer hair
Publications
The most up-to-date and comprehensive overview of my publications can be found here:
My PhD thesis is freely available for download at the official Cambridge University repository here.
The 279 pages of the thesis were written with a general audience in mind and introduce concepts both from supply chain management as well as from AI.
PhD research
My doctoral research focused on improving supply chain visibility by extracting supply networks from natural language text, such as news articles.
[I will add more details here soon.]
Vector graphics and AI
I have always been interested in graphic design.
While at school, I earned some money by designing websites.
At university, I worked for a student consultancy on the side and, as one of my consulting projects, I designed a corporate design for a client, including many logo drafts and the final logo.
During my PhD as a side project: Markedly and Logobot (2017-2018)
Later, during my PhD, I convinced a few talented friends of mine to co-found a company with me, called Markedly Ltd. The idea was to generate vector logos and icons using AI under the brand of "Logobot" or "Logolab" (our initial name). This was the time when thenounproject.com started to offer pre-made vector icons via API and when Logojoy (now called Looka) allowed users to create logos based on keywords. Logojoy initially only used some pre-made static templates for these logos. So, we started to make the logos more intelligent by adding basic AI models.

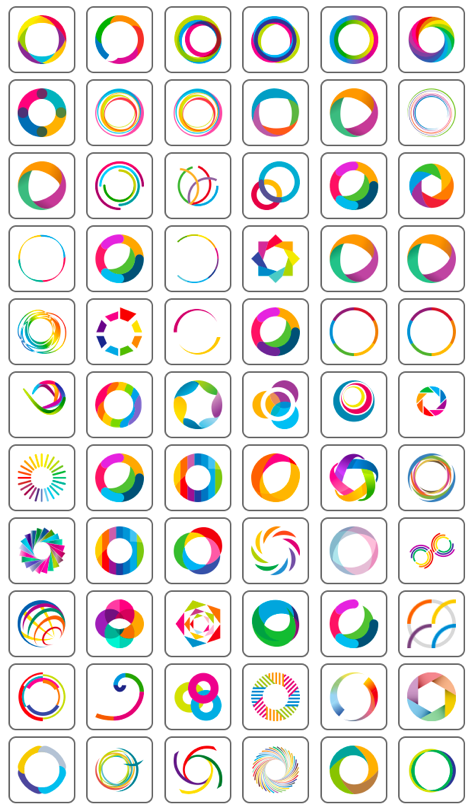
You may be able to see in the image above that we were able to automatically identify which icon matched the keyword and also visually resembled the shape of a letter in the brand name. For some logos, we then replaced the letter by the icon. We did the same for the counter space in letters, e.g. we first filled the letter "O" and then deducted an octopus icon (similar in shape to the inner, negative space of the letter) from the letter.
Below, you can see some of the logos we auto-generated. The results were truly magical (at the time, at least - now, we have image models for raster images) because they surprised in their seeming creativity. The system could assess so many possible combinations of icons and letters - more than humans could ever do in their brains. You can still see the debugging information printed into the SVGs: I had defined many dozens of logo generation functions that implemented a different logo design strategy: some used AI, some did not.






I also never liked that the icons used were identical for all users. This defeated the purpose of corporate identity and logos. So, we ran many experiments on trying to generate custom icons with GANs and other generative models of the time.
Unfortunately, we were too early and I also still needed to convince my PhD supervisor of my ideas for my PhD research which was completely unrelated to vector graphics. But I won the "Young Entrepreneur of the Year Award" for this work from the Cambridge University Entrepreneurs in 2017.
Parallel to my consulting work: Online book on Deep Learning with Vector Graphics
Since that time, a significant number of my synapses have remained reserved for this topic. In 2021, I started to write an online book on the topic of "Deep Learning with Vector Graphics" which you can find here. I also personally spoke with many of the authors of seminal papers in the field.
SVG collection
Since my PhD times, I have been collecting SVGs in a large database comprising 50+ million of unique SVGs. Scripts extract SVGs from public websites, perform some preprocessing steps and store new ones in a MongoDB. If the SVG is already in the database, I also check if the SVG came with a filename. If so, I store one unique filename per domain in a separate MongoDB collection. This way, I can use the collected filenames for the same SVG as indicators for the content or labels.
Labelling app
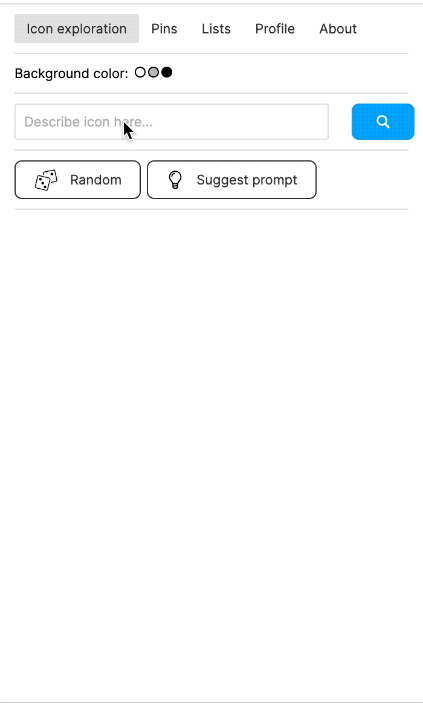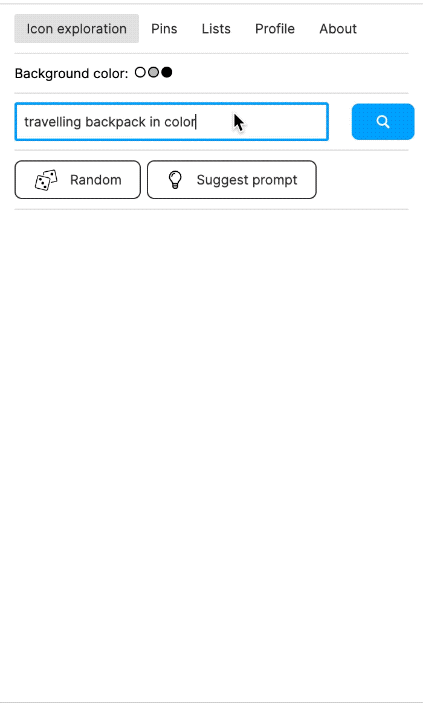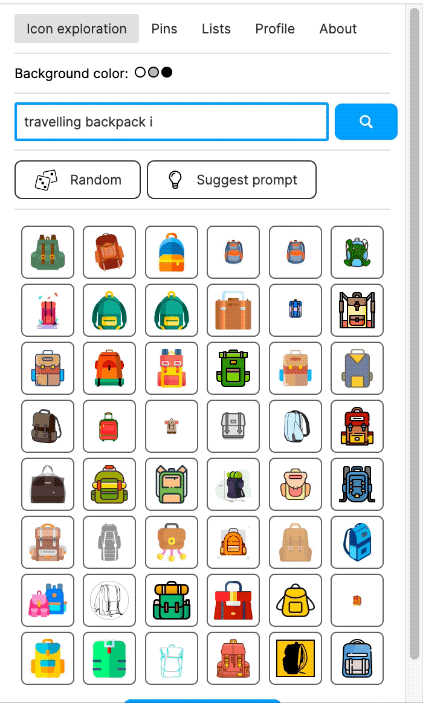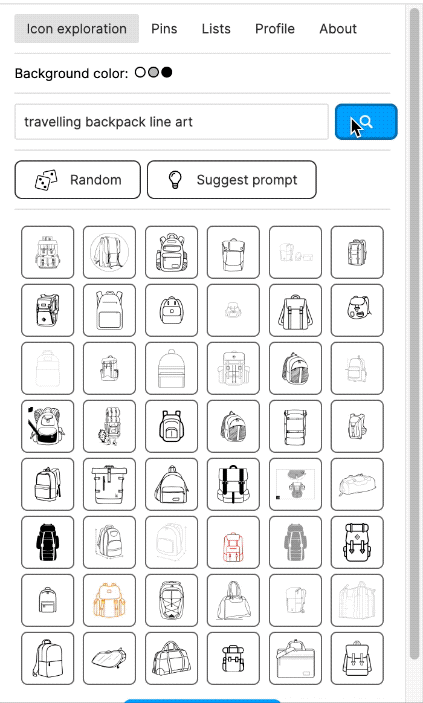
To view collected SVGs and to label them, I manually built a local Web application. It allowed me to view the most recently added SVGs. But I had also CLIP-embedded at least 20 million of the rasterised SVGs. Using a vector database (I used Milvus), I was then able to search SVGs by a text description. And I could click on any icon to find the most similar SVGs in the database. The latter enabled a mass labelling mode: I could view the 1,000 most similar SVGs on one screen, select all of them at once (or deselect a few) to assign a label to them.
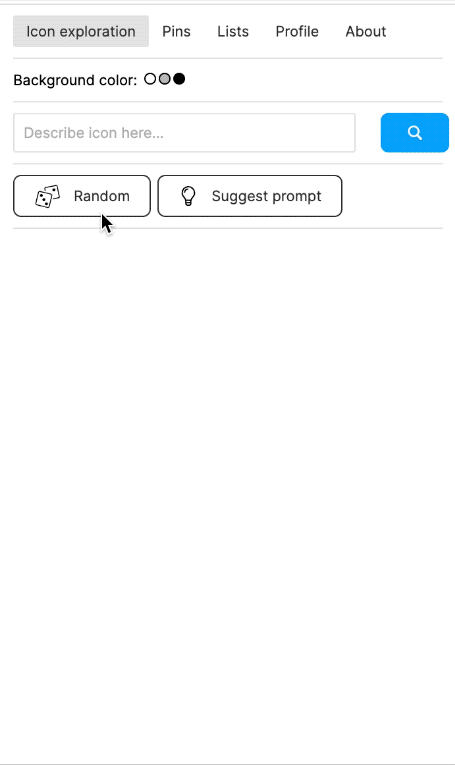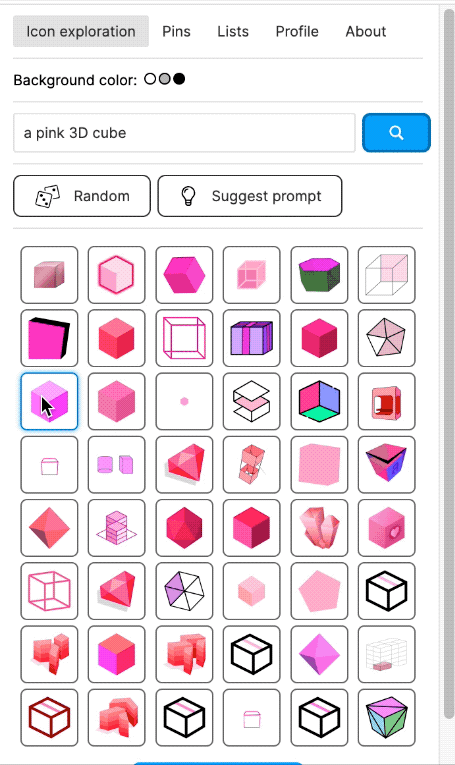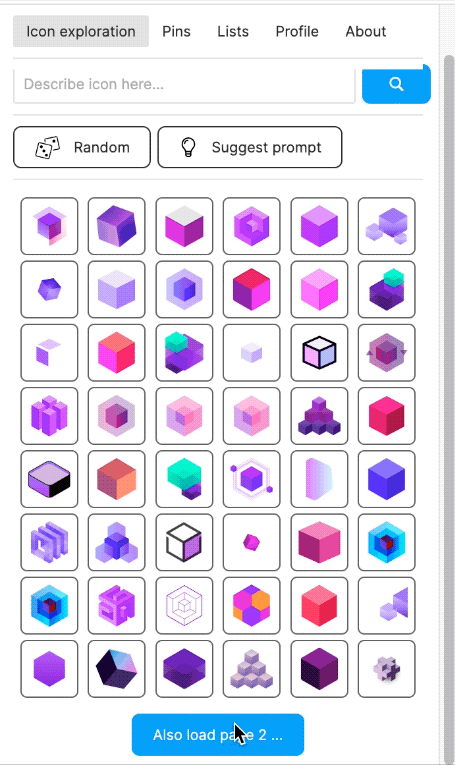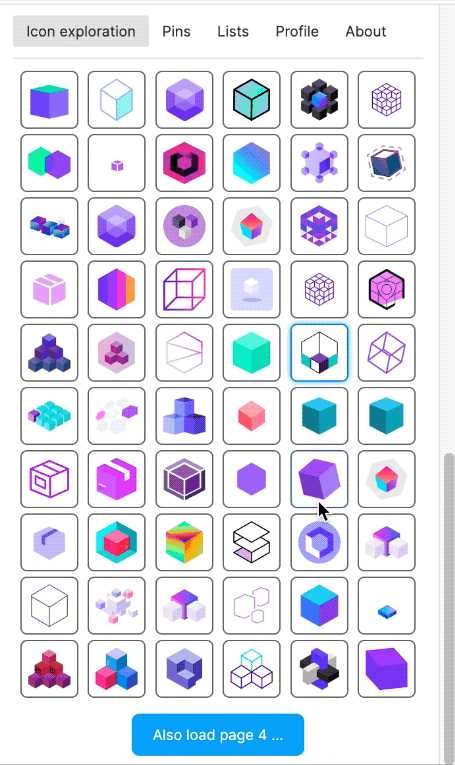
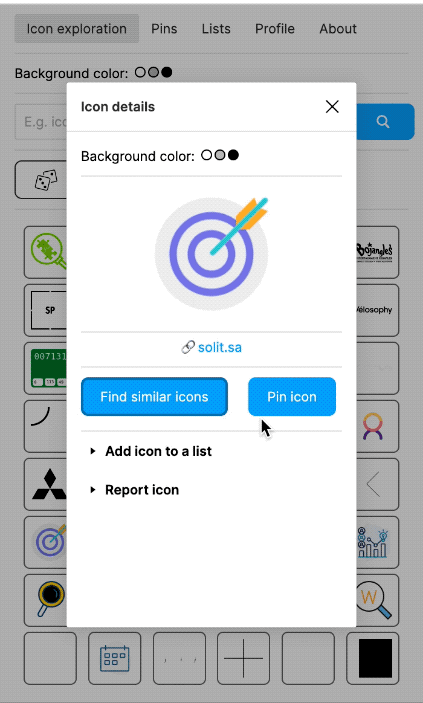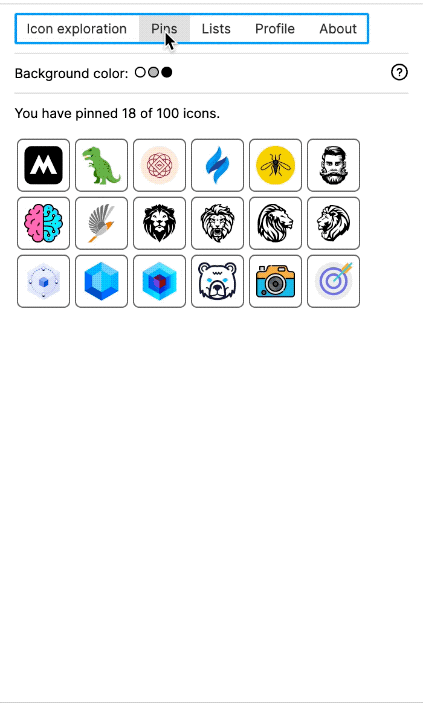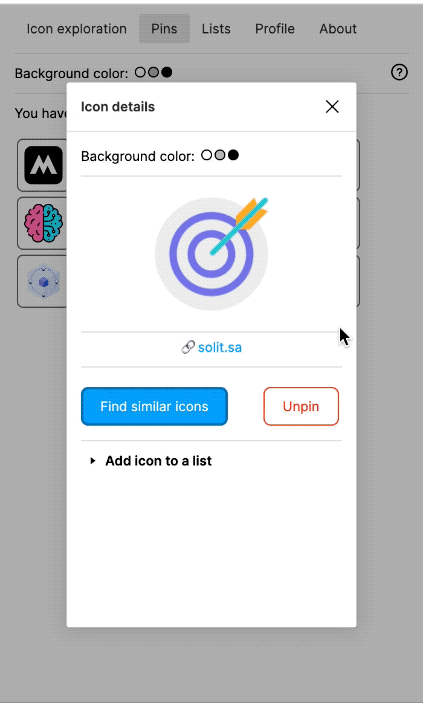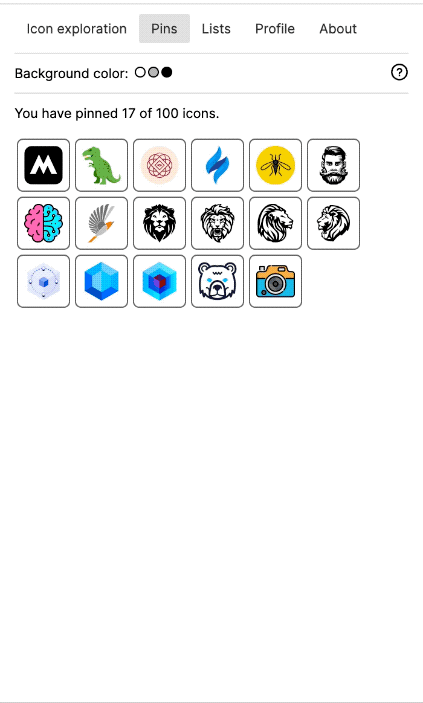
Figma plugin called "Quiver" (2022)
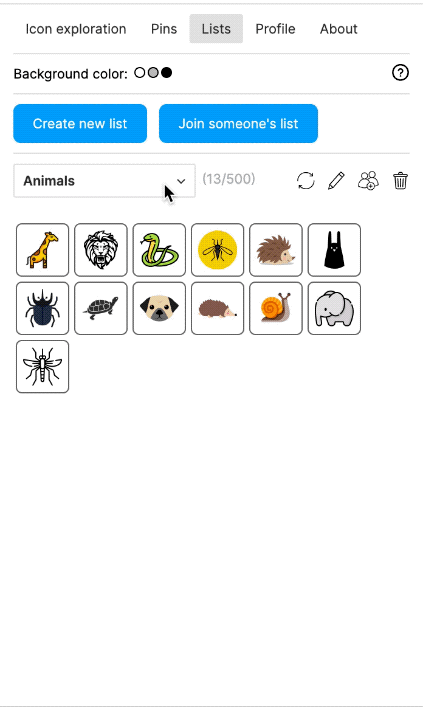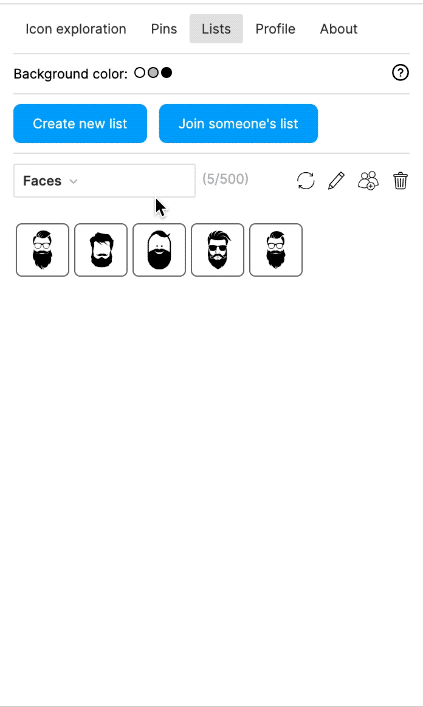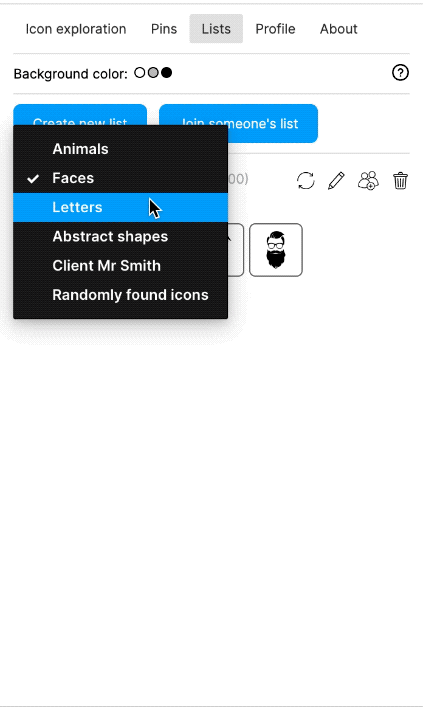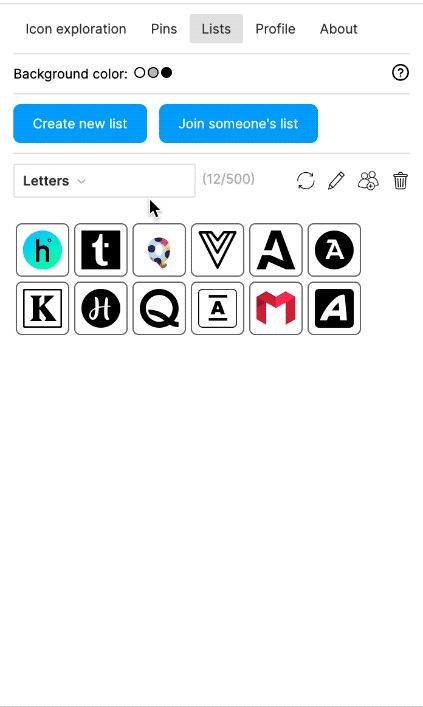
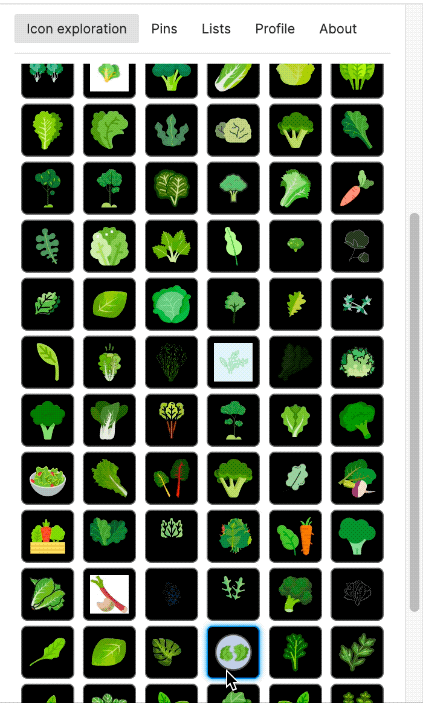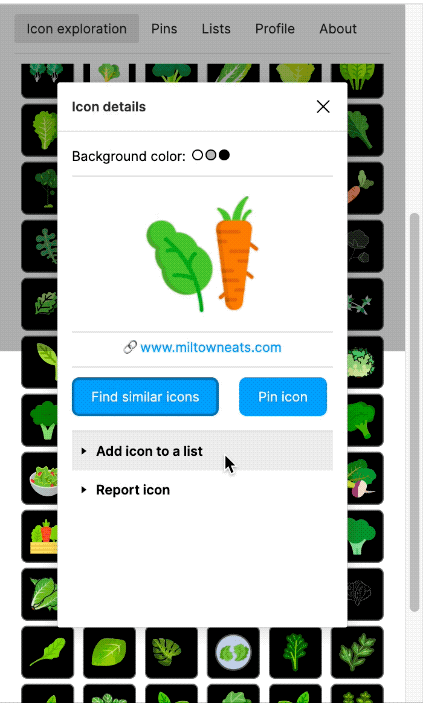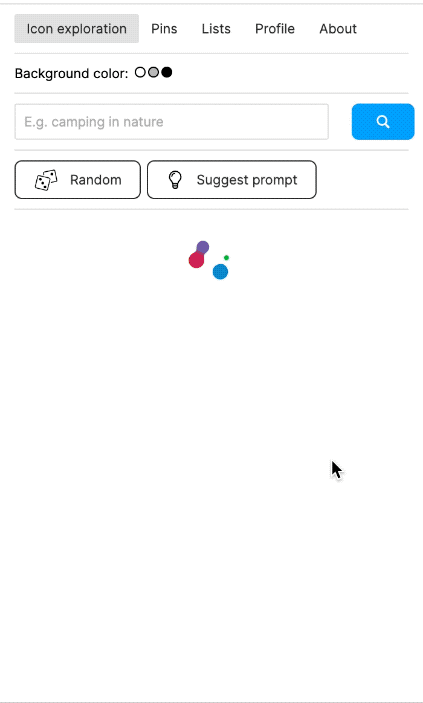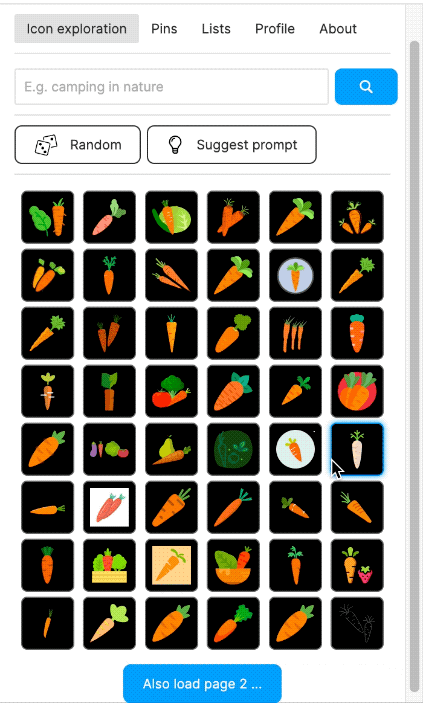
I also built a Figma plugin, which I called "Quiver AI". I never publicly released it apart from also creating a website for it. The Figma plugin was supposed to help designers with inspiration on how concepts could be visualised. It used the same semantic search I had already implemented for my labelling app. Google Image Search was fairly terrible for icons at the time at least. I liked the name Quiver because I was working with vector graphics (a vector often being represented as an arrow) and using Deep Learning I wanted to create an infinite repository for vector graphics. I could not allow the import of the SVGs into Figma because I wanted to respect the rights of the original creators of the SVGs. I could only show a raster version and a link to the website where the SVG had been found. But because I had collected all the SVGs, I was able to show clean raster images in identical resolution and sizes.









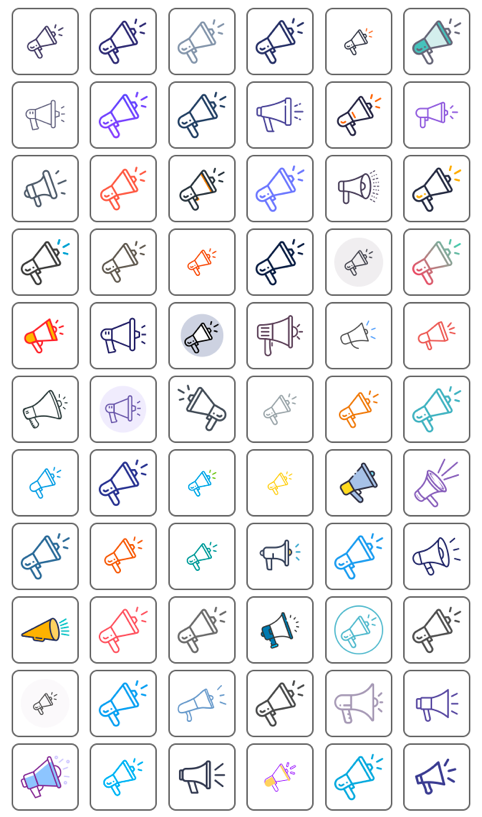







The Figma plugin could do more than just a semantic search; users should also be able to collect and manage icons. Vibe coding was not a thing yet, and so I used the Figma Preact toolkit from YuanQing and handcoded the rest.
line.art
I have also been fascinated by continuous, single line art drawings. So much so, that I spent an insane amount of money on the domain line.art and have been working on the idea using Fourier Series and other techniques.
"Fontitude"
I also worked on a project which I called "Fontitude" which was supposed to be an art work. Using my scraper that were running 24/7 anyways collecting SVGs, I also collected unique fonts. I did not want to use the fonts for any other purpose than to create the art work. The piece should consists of the text "Threshold of origininality" but each letter of the text should consist of a million smaller letters from a million different fonts that were all sorted by similarity. Again, I simply used a CLIP-embedding cosine similarity for this purpose. I also used UMAP to reduce the dimensionality of the letter embeddings to 2D and Mario Klingemann's RasterFairy.
CV
[I will add more details here soon.]